
Fraud is scaling faster than the people fighting it.
Synthetic identities, coordinated account rings, automated attacks — adversaries are already using AI to generate fake profiles, rotate device fingerprints, and probe detection systems at scale. Meanwhile, the analyst on the other end is still manually pulling evidence from four different tools, cross-referencing accounts in spreadsheets, and writing case summaries by hand.
The manual investigation process can’t keep up. But replacing analysts with AI isn’t the answer either — fraud decisions carry real consequences, and “the model said so” isn’t an acceptable audit trail.
The answer is somewhere in the middle: an AI co-investigator that gathers evidence autonomously, cites its sources, and requires human approval for sensitive actions. That’s what I built this week — a working prototype of an AI-native fraud investigation agent.
The Problem: Investigation, Not Detection
Most fraud platforms are strong at detection — scoring engines, graph analysis, model explainability. The hard part is what happens after a case is flagged.
An analyst receives a flagged transaction. They need to:
- Search for related user profiles (multi-accounting)
- Check if the user is part of a fraud ring
- Understand why the transaction was flagged
- Read the model’s feature importances
- Synthesize all of this into a case summary
- Decide what to do next
Each step involves a different internal tool. The synthesis is manual. The report is unstructured. And the audit trail is whatever the analyst remembers to write down.
This is the workflow that AI agents are built for. Not replacing the analyst’s judgment, but automating the evidence-gathering and synthesis so they can focus on the decision.
The Agent: Typed Tools + Agentic Reasoning
The prototype is a CLI agent that takes a fraud case and investigates it autonomously. The agent has access to four typed tools:
closest_user_search— find related profiles by shared identifiers (device, email, phone, IP) for multi-accounting detectioncluster_search— surface coordinated account clusters and fraud ringstransaction_explainer— plain-language summary of why a transaction was flagged, with top risk signalsmodel_explainer— feature importances and model-level insights for auditing risk scores
Each tool is defined as a typed contract — Pydantic request/response schemas with validation, RBAC, and full invocation tracing. The agent doesn’t call tools through loose string prompting; it calls structured APIs that produce auditable records.
Here’s what happens when you point it at a flagged crypto transaction:
$ nofraud crypto_new_account --verbose
Agent turn 1: calls all 4 tools in parallel
→ closest_user_search: 2 matches (91%, 84% similarity)
→ cluster_search: part of risk_ring_12 (3 accounts)
→ transaction_explainer: new account + high-risk merchant + velocity spike
→ model_explainer: device overlap 34%, account age 27%, velocity 18%
Agent turn 2: synthesizes report
→ RECOMMENDATION: Block transaction (95% confidence)
→ Flag entire cluster for review
→ Analyst approval required: YesClaude receives the case context and tool definitions, reasons about which tools to call, executes them in parallel, then synthesizes a structured report. The report explicitly separates:
- Verified facts — directly from tool outputs
- Model signals — from the explainability layer
- Recommendation — with a confidence level
- Approval requirement — flagged when the action is sensitive
This separation matters. In fraud, you need to know why the system is recommending something and which evidence supports it. “The AI said block it” is not an acceptable answer for compliance.
An AI co-investigator should surface suspicious signals quickly, but still present evidence clearly for analyst judgment.
The Architecture
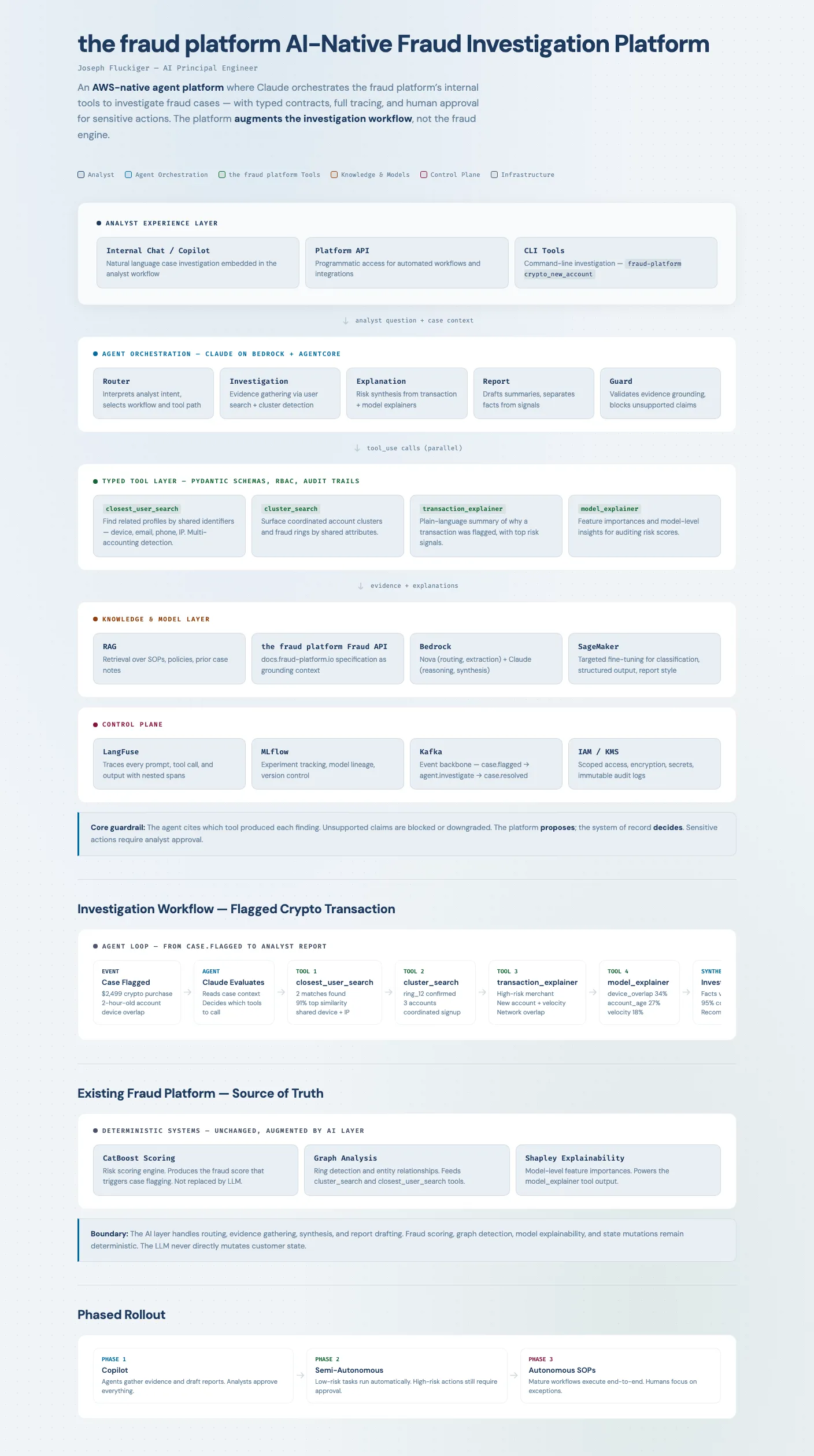
Click the diagram to view the full interactive version.
The platform sits between the existing fraud detection systems (scoring, graph analysis, explainability) and the analyst workflow. It doesn’t replace the fraud engine — it augments the investigation layer.
Five components:
-
Agent orchestration — Claude on Bedrock reasons over analyst questions, selects tools, and synthesizes evidence. The agent is accessible through chat, API, and CLI — AI-first experiences beyond a single interface.
-
Typed tool layer — Four internal capabilities exposed as versioned contracts with schemas, validation, and full invocation tracing. Every recommendation is traceable to specific tool outputs.
-
Knowledge layer — RAG over SOPs, policies, and prior case notes. Domain grounding without fine-tuning.
-
Model layer — Cheaper models for routing and extraction; stronger models only for complex reasoning. Fine-tuning targeted at narrow tasks where it measurably helps.
-
Control plane — LangFuse traces every prompt, tool call, and output. Kafka provides the event backbone so workflows are resumable and auditable.
Core guardrail: The platform proposes; the system of record decides. Unsupported claims are blocked or downgraded. The agent never directly mutates customer state.
Why Typed Tool Contracts Matter
The most important design decision isn’t the model choice or the infrastructure — it’s treating tools as typed, auditable contracts.
In most agent demos, tools are loose functions with string descriptions. The agent might hallucinate parameters, call tools that don’t exist, or produce outputs that can’t be verified. In fraud investigation, that’s unacceptable.
Each tool in this prototype has:
- A Pydantic schema for request and response
- Input validation before execution
- An audit record (tool name, request payload, response payload, timestamp)
- Traceable lineage through LangFuse
This means if an analyst asks “why did the system recommend blocking this transaction?”, you can trace the answer back to specific tool calls with specific inputs and outputs. The audit trail is automatic, not manual.
In production, you’d swap the mock handlers for real API endpoints. The orchestration, tracing, and audit contracts stay the same.
The Investigation Sequence

Click the diagram to view the full interactive version with Mermaid sequence diagram.
The workflow from case to resolution:
- Fraud platform publishes
case.flaggedto Kafka - Agent evaluates the case context and decides which tools to call
- All four tools execute in parallel — the agent doesn’t wait sequentially
- Agent synthesizes evidence, separating facts from model signals
- Report is produced with confidence level and approval flags
- Analyst reviews evidence and confirms or rejects the recommended action
The parallel tool execution is key. A human analyst would call these tools one at a time, reading each result before deciding what to check next. The agent calls all four simultaneously and synthesizes the combined evidence — a fundamentally faster workflow that still produces a human-readable, auditable output.
Observability as a First-Class Concern
Every agent run produces a LangFuse trace with nested spans:
- Root trace:
investigation-{case_id} - Child spans: one per tool call with input/output captured
- Events: recommendation generated, investigation completed
This isn’t aspirational — it’s working in the prototype. Run a case, open LangFuse, and you see the full investigation: which tools were called, what they returned, how the recommendation was derived.
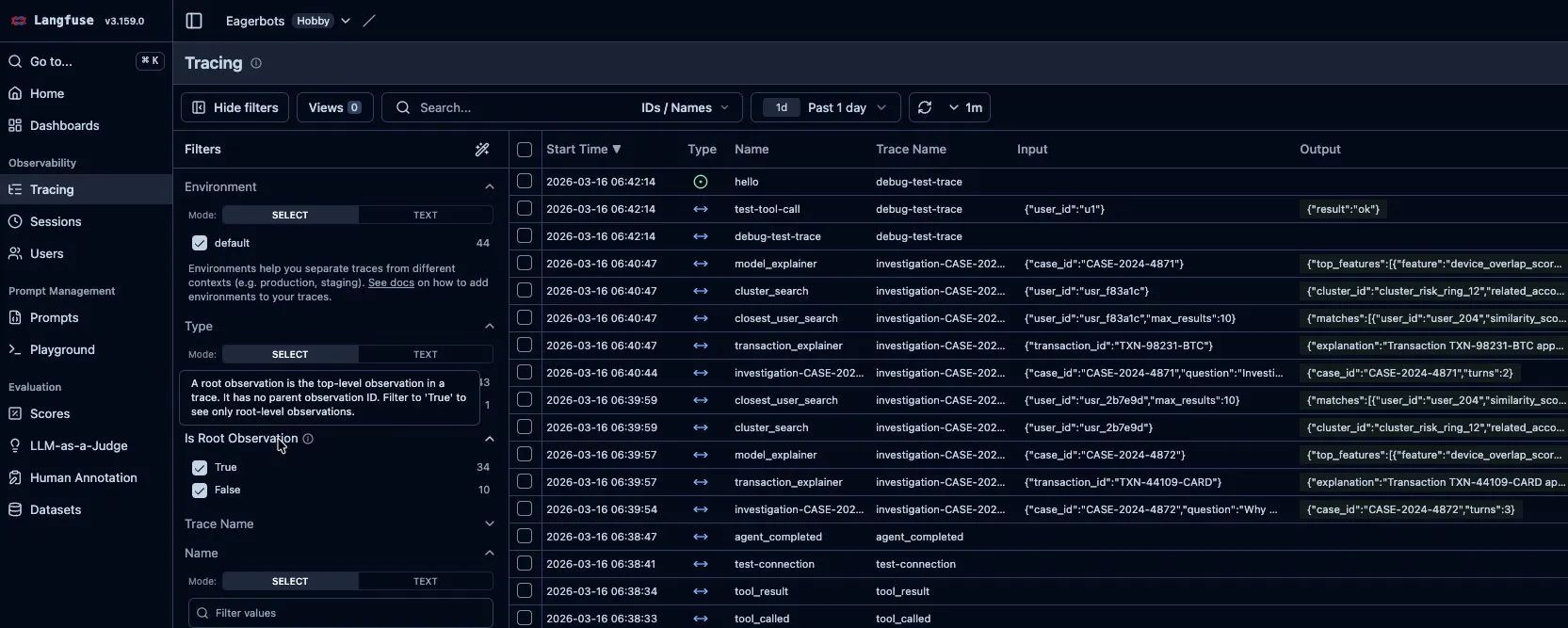
Real LangFuse traces from the prototype. Each investigation produces traces for closest_user_search, cluster_search, transaction_explainer, and model_explainer — with full input/output captured. You can see multiple case investigations (CASE-2024-4871, CASE-2024-4872) with their tool calls and completion events.
For a fraud platform, this observability is non-negotiable. Regulators want audit trails. Analysts want to understand the reasoning. Engineering wants to monitor for drift, unsupported claims, and tool failures. LangFuse gives you all of that from day one.
Fine-Tuning: Targeted, Not Broad
A common instinct with LLM projects is to fine-tune on everything. For fraud investigation, that’s the wrong approach.
Retrieval + tool calling comes first. For most analyst workflows, the value comes from evidence access and orchestration quality — not from training a model on internal data.
Fine-tuning is justified only for narrow, high-signal tasks where it measurably improves reliability, latency, or cost:
| Task | Why fine-tune |
|---|---|
| Routing / classification | Lower latency, cheaper than a frontier model |
| Structured output | Schema conformance reliability |
| Transaction explanations | Consistent normalization across types |
| Report drafting | Match the company’s internal style |
The prototype includes a fine-tuning evaluation pipeline: 10 realistic fraud cases, a golden eval set, chat-style SFT data, and an sklearn classification baseline. The baseline establishes the floor — any fine-tuned model needs to beat it on the metrics that matter.
Infrastructure: AWS-Native
Everything runs within the company’s AWS data boundary:
- Bedrock for model access (Nova for routine tasks, Claude for hard reasoning)
- EKS for tool services
- Kafka (MSK) for event-driven, resumable workflows
- SageMaker for targeted fine-tuning
- S3/Iceberg/Athena for data curation
- IAM, KMS, Secrets Manager, CloudWatch for the full security and audit stack
Cost control is designed in: cheaper models handle routing and extraction; the expensive model only fires for complex synthesis. Per-case token and tool cost attribution makes spend visible.
The Phased Rollout
You don’t ship autonomous fraud agents on day one. The rollout is phased:
Phase 1 — Copilot: The agent gathers evidence and drafts reports. Analysts approve everything. This builds trust and collects feedback.
Phase 2 — Semi-autonomous: Low-risk tasks (lookups, summarization) run automatically. High-risk actions still require human approval.
Phase 3 — Autonomous SOPs: Mature, repeatable workflows execute end-to-end with full audit trails. Humans focus on exceptions and escalations.
Each phase widens the automation boundary only after the platform has earned trust through observability, evaluation, and analyst feedback loops.
The Arms Race
Fraud is an adversarial domain. The attackers are already using AI — generating synthetic identities, automating account creation, probing detection rules with learned strategies. The defensive tooling needs to match that pace.
But the defense has an advantage the attackers don’t: structured internal data. The fraud platform knows the graph of account relationships, the model’s feature importances, the transaction history, the cluster memberships. An AI agent that can orchestrate these tools in real time, synthesize the results, and present a traceable recommendation to an analyst — that’s a force multiplier the manual process can’t match.
The pattern generalizes beyond fraud. Any domain where an expert manually gathers evidence from multiple systems, synthesizes findings, and produces a structured recommendation — compliance, security operations, medical diagnosis, insurance claims — is a candidate for this architecture: typed tools + agentic reasoning + human-in-the-loop oversight + full observability.
What I Learned
Building this prototype reinforced a few principles:
-
A working demo beats a perfect diagram. The CLI agent running a real investigation is more convincing than any number of architecture slides.
-
Typed contracts are the foundation. Without Pydantic schemas and audit records, the agent is just a chatbot with API access. With them, it’s a traceable, testable system.
-
Observability from the start, not later. Wiring LangFuse into the prototype from day one meant every run produced evidence of how the system works. Retrofitting observability is much harder.
-
Fine-tuning is optimization, not architecture. The system works with a base model and tool calling. Fine-tuning makes specific tasks faster or cheaper — it’s not the core design.
-
Human-in-the-loop isn’t a limitation — it’s the feature. For fraud, the analyst’s judgment is the product. The AI makes that judgment faster and better-informed, not unnecessary.
A final view of the network challenge: connecting related accounts fast enough to stop coordinated fraud.
The full prototype — CLI agent, typed tools, LangFuse tracing, fine-tuning pipeline, 14 unit tests — is available on GitHub.